

Índice
Imagine a cena:
Um influenciador com milhões de seguidores publica o link da promoção exatamente às 20h. Em pouco tempo, os acessos decolam. De algumas dezenas de acessos por minuto, passa para centenas de milhares e, em casos maiores, milhões de usuários simultâneos.
Esse tipo de pico não é exceção, na verdade isso é praticamente a regra em campanhas promocionais de grande escala. O mercado de promoções e ativações de marca reflete isso: o setor de live marketing movimentou R$ 110 bilhões em 2024 (dados do Anuário Brasileiro de Live Marketing da AMPRO), com uma fatia enorme vinda de ações nacionais que envolvem sorteios, premiações instantâneas, gamificação e incentivos B2B.
O brasileiro tem uma cultura forte de participar de promoções e sorteios com muito entusiasmo, especialmente quando a ação é digital e acessível. Mas exatamente por causa dessa adesão forte, qualquer interrupção (falha no site, lentidão ou queda) pesa muito na percepção da marca. O que acontece nesse momento define tudo: a campanha vira case de sucesso… ou vira meme de “site caiu” nas redes.
Depois de conduzir centenas de campanhas nacionais e internacionais aqui no Grupo Polgo, aprendemos na prática o essencial para não deixar isso acontecer: projetar uma infraestrutura elástica, que escala automaticamente nos picos imprevisíveis e se torna econômica quando a demanda volta ao normal.
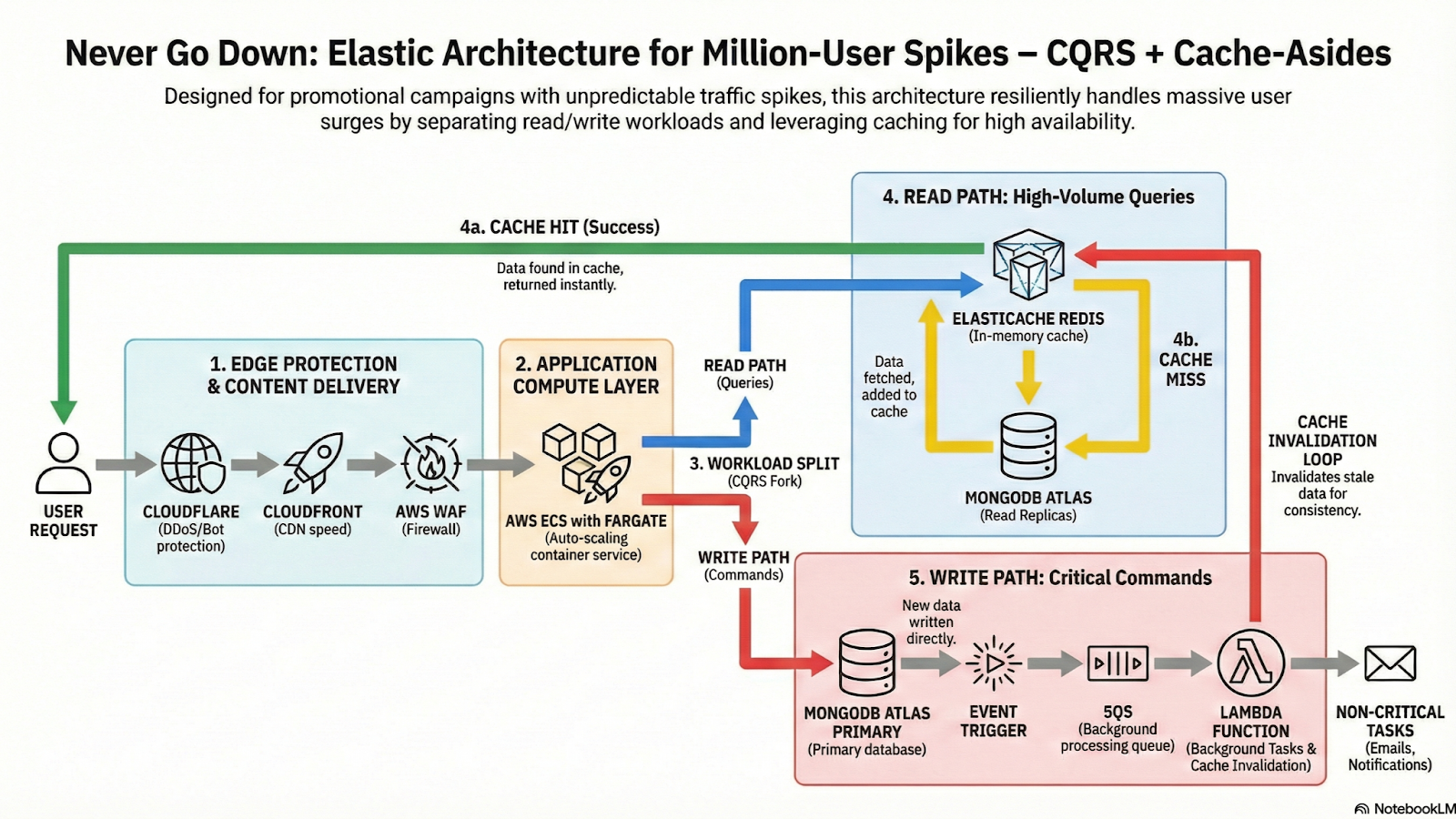
Abrindo o capô: a jornada real de uma campanha em meio ao caos
O link viraliza e milhares de cliques chegam de uma vez, muitos do Brasil, mas também de fora, via redes sociais ou anúncios. O primeiro risco? Ataques DDoS, bots e tráfego malicioso colocando em risco a campanha inteira antes mesmo dela começar.
- A Cloudflare, na borda global, filtra isso em escala mundial. WAF + mitigação avançada de DDoS bloqueiam tráfego malicioso antes de chegar à AWS. Além de proteger, isso desonera toda a infraestrutura interna.
Com o usuário legítimo chegando, a landing page precisa abrir rápido, especialmente no Brasil, onde a velocidade da conexão varia muito entre regiões.
- Aqui entra o Amazon CloudFront (CDN), distribuindo conteúdo estático (imagens, JavaScript, CSS e páginas iniciais) em PoPs locais no Brasil e no mundo, com cache inteligente na borda. Resultado: carregamento em milissegundos para usuários de São Paulo a Manaus, e também para quem acessa de Portugal ou dos EUA.
Escalar sem cair (e sem gastar além do necessário)
A partir daí, começa a interação real: consumidores se cadastrando, enviando cupons, girando roletas e consultando números da sorte. Mesmo assim, ainda existe o risco de tráfego abusivo ou padrões específicos de fraude (como tentativas repetidas de resgate).
- AWS WAF reforça a proteção: regras customizadas e managed rulesets aplicadas diretamente na AWS (integradas com CloudFront e ALB) bloqueiam exploits layer 7 adaptados ao nosso domínio, uma camada extra de defesa granular para promoções.
Com o tráfego malicioso mitigado, o foco passa a ser a aplicação principal: APIs e regras de negócio precisam escalar de dezenas para milhares de instâncias em segundos.
- AWS ECS com Fargate + Auto Scaling resolve isso: contêineres serverless sobem automaticamente com base em métricas reais (CPU, requisições), mantêm baixa latência durante o pico e reduzem sozinhos depois. Performance alta, sem gerenciamento manual e com custo alinhado ao uso real.
Quando a ação exige escrita (cadastro do consumidor, resgate de prêmio), o desafio é separar leituras rápidas de escritas críticas.
- A arquitetura CQRS entra aqui. Comandos (escritas) vão direto para o nó primário do banco. Consultas leem das réplicas. Assim, milhões de leituras escalam sem comprometer a consistência das gravações.
O próximo gargalo natural são as consultas repetidas: consumidores checando saldo, status e premiações várias vezes por minuto.
- Para isso, usamos Elasticache (Redis) como cache distribuído. Resultados com TTL são armazenados em memória e retornados em microssegundos (sim, micro, e não milissegundos), reduzindo drasticamente a carga no banco durante o pico.
No núcleo dos dados, o banco precisa suportar CQRS, alta concorrência, auditoria e operações atômicas.
- O MongoDB Atlas, com Replica Set (1 primário para gravações + 2 secundários para leituras), garante failover automático, alta disponibilidade e distribuição de carga. Os dados permanecem sempre disponíveis, criptografados e auditáveis, essenciais para ambientes regulados.
Nem tudo precisa ser síncrono
Processar cupons fiscais, enviar e-mails, atualizar relatórios ou receber vendas do PDV não é preciso travar o usuário.
- Aqui entram Amazon SQS + AWS Lambda: filas resilientes com retry automático e Lambdas que escalam em paralelo. O usuário recebe resposta imediata, enquanto o processamento pesado acontece em background, de forma econômica e confiável.
Essa arquitetura transforma picos imprevisíveis em uma experiência fluida e confiável. Permite mecânicas complexas como gamificação em tempo real, dashboards atualizando ao vivo e validações instantâneas no PDV, tudo com confiança total.
O principal aprendizado a partir de centenas de campanhas conduzidas na Polgo é que alta disponibilidade gera tranquilidade real para quem está do outro lado: agências, marcas, times de marketing e de desenvolvimento. Quando o sistema se mantém estável, o engajamento cresce de forma natural, as campanhas fluem melhor e a marca sai fortalecida, sem a necessidade de explicar depois por que “caiu”.
Para conversar sobre como blindar tecnicamente uma promoção sem complicar a operação, basta clicar aqui e entrar em contato no nosso site ou comentar.
Boas campanhas.